Azure Databricks is Easier Than You Think
Download as PPTX, PDF2 likes1,922 views

Spark is a fast and general engine for large-scale data processing. It supports Scala, Python, Java, SQL, R and more. Spark applications can access data from many sources and perform tasks like ETL, machine learning, and SQL queries. Azure Databricks provides a managed Spark service on Azure that makes it easier to set up clusters and share notebooks across teams for data analysis. Databricks also integrates with many Azure services for storage and data integration.









































Azure Databricks is Easier Than You Think
- 1. Ike Ellis Moderated By: Rayees Khan Azure Databricks is Easier than you Think
- 2. If you require assistance during the session, type your inquiry into the question pane on the right side. Maximize your screen with the zoom button on the top of the presentation window. Please fill in the short evaluation following the session. It will appear in your web browser. Technical Assistance
- 3. PASS’ flagship event takes place in Seattle, Washington November 5-8, 2019 PASSsummit.com PASS Marathon: Career Development October 8, 2019 Upcoming Events
- 4. Ike Ellis Solliance, Crafting Bytes Azure Data Architect Whether OLTP or analytics, I architect data applications, mostly on the cloud. I specialize in building scalable and resilient data solutions that are affordable and simple to maintain. Author Developing Azure Solutions (2nd Ed) Power BI MVP Book Speaker • PASS Summit Precon (Nov 2019) • SDTIG • San Diego Power BI & PowerApps UG • PASS Summit Learning Pathway Speaker • Microsoft Data & AI Summit (Dec 2019) /ikeellis @ike_ellis ike@ikeellis.com
- 5. Ike Ellis Moderated By: Rayees Khan Azure Databricks is Easier than you Think
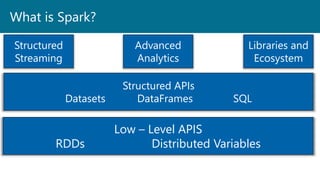
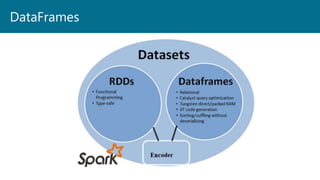
- 6. What is Spark? Low – Level APIS RDDs Distributed Variables Structured APIs Datasets DataFrames SQL Structured Streaming Advanced Analytics Libraries and Ecosystem
- 7. ETL Predictive Analytics and Machine Learning SQL Queries and Visualizations Text mining and text processing Real-time event processing Graph applications Pattern recognition Recommendation engines What applications use Spark?
- 8. Not an OLTP engine Not good for data that is updated in place But if it has to do with data engineering and data analytics, spark is pretty versatile: IOT Streaming Pub/Sub Notifications Alerting What can’t you do with Spark?
- 9. Scala Python Java SQL R C# Some clojure Programming Interfaces with Spark
- 10. ETL Predictive Analytics and Machine Learning SQL Queries and Visualizations Text mining and text processing Real-time event processing Graph applications Pattern recognition Recommendation engines What applications use Spark?
- 11. Not an OLTP engine Not good for data that is updated in place But if it has to do with data engineering and data analytics, spark is pretty versatile: IOT Streaming Pub/Sub Notifications Alerting What can’t you do with Spark?
- 12. Scala Python Java SQL R C# Some clojure Programming Interfaces with Spark
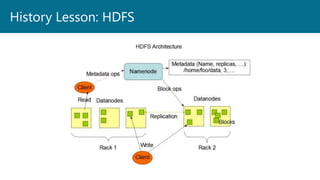
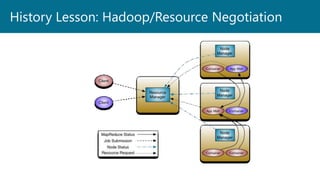
- 15. History Lesson: Hadoop/Resource Negotiation
- 17. Local/network file systems Azure Blob Storage Azure Data Lake Store (gen 1 & gen 2) SQL Server or other RDBMS’s Azure CosmosDB or other NoSQL stores Messaging systems (like Kafka) Input and Output Types
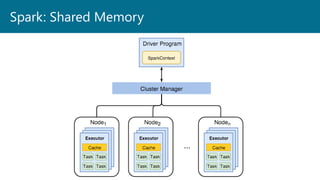
- 19. All run in JVMs JVMs can all be on one machine or separate machines Don’t think of them as physical locations Spark components
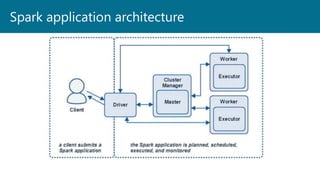
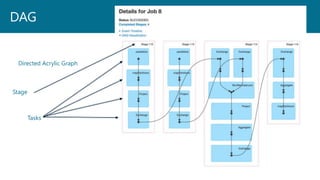
- 20. The process that submits applications to Spark Plans and coordinates the application execution Returns status to the client Plans the execution of the application Creates the DAG Keeps track of available resources to execute tasks Scheduling tasks to run “close” to the data where possible Coordinate the movement of data when necessary Spark Driver
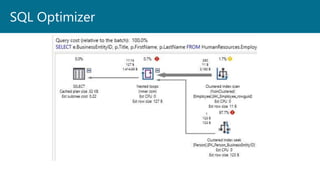
- 22. SQL Optimizer
- 23. Spark delays execution until an action is called, like collect() This allows Spark to delay the creation and execution of the DAG until it sees how the code is being used. For instance, it might find an optimal way to execute something if only the MAX or COUNT is being requested The DAG is then managed across executors by the driver All statements before the action are just parsed and not executed until Spark sees the action Lazy Evaluation
- 24. Transformations Data manipulation operations Actions Requests for output .Collect() .Show() The driver is also the UI in spark on port 4040. Subsequent applications are port 4041, 4042, etc Driver creates DAG for Two Items
- 25. Executors Host process for spark tasks Can run hundreds of tasks within an application Reserve CPU and memory on workers Dedicated to a specific Spark application and terminated when the application is done Worker Hosts the Executor Has a finite number of Executors that can be hosted Spark Executors and Workers
- 26. Allocate the distributed resources Can be separate processes, or in stand-alone mode, can be the same process Spark Master Requests resources and assigns them to the Spark Driver Serves a web interface on 8080 Is not in charge of the application. That’s the driver. Only used for resource allocation Spark Master & The Cluster Manager
- 27. Solves the following issues: Difficult to setup Getting the right node count in the cluster is not elastic Lots of prerequisites Lots of decisions to make regarding scheduling, storage, etc. Azure Databricks
- 28. Azure Blob Storage Azure Data Lake Store Gen 1 Azure Data Lake Store Gen 2 Azure CosmosDB Azure SQL Database Azure Database Azure SQL Datawarehouse Azure Databricks Storage Options for Files
- 29. Azure Databricks has a secure and reliable production environment in the cloud, managed and supported by Spark experts. You can: Create clusters in seconds. Dynamically autoscale clusters up and down, including serverless clusters, and share them across teams. Use clusters programmatically by using the REST APIs. Use secure data integration capabilities built on top of Spark that enable you to unify your data without centralization. Get instant access to the latest Apache Spark features with each release. Azure Databricks over Spark OnPrem
- 31. With the Serverless option, Azure Databricks completely abstracts out the infrastructure complexity The workspace is different than the clusters. The workspace (notebook code) can be saved and reused while the clusters are spun down and not billing Azure Databricks Serverless
- 32. A notebook is: a web-based interface to a document that contains runnable code, visualizations, and narrative text one interface for interacting with Azure Databricks Azure Databricks Notebooks
- 33. Power BI Excel Azure Data Factory SQL Server CosmosDB Microsoft is Using Spark Everywhere
- 34. Resilient Distributed Dataset Stored in memory Created in reaction to Hadoop always saving intermediate steps to the disk Much, much faster RDDs become interactively explored once loaded Because of the speed, used often to clean data (pipelines) or for machine learning Basics of RDDs
- 35. If a node performing an operation in spark is lost, the dataset can be reconstructed Spark can do this because it knows the lineage each RDD (the sequence of steps needed to create it) RDDs - Resilient
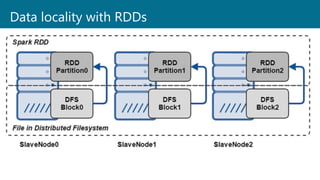
- 36. Data is divided into one or many partitions Distributed as an in-memory collection of objects across worker nodes RDDs are shared memory across executors (processes) in individual workers (nodes) RDDs - Distributed
- 37. Records are uniquely identifiable data collections within the dataset Partitioned so that each partition can be operated on independently Called a Shared Nothing architecture Are immutable datasets. We don’t change an existing one as much as we create a whole new one Can be relational (tables with rows and columns) Can be semi-structured: JSON, CSVs, PARQUET files, etc RDDs - Datasets
- 38. Files SQL Server or other RDBMSs Azure CosmosDB or other NoSQL stores Stream Programmatically Loading data into RDDs
- 39. Data locality with RDDs
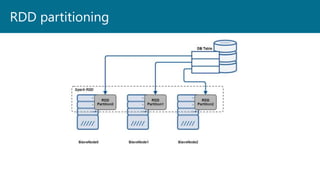
- 40. RDD partitioning
- 41. If you create too many RDD partitions against a cloud service (SQL Server, CosmosDB, Azure Blob Storage), you might get flagged as a DDOS attack Careful with partitioning!
- 42. DataFrames
- 43. PySpark has an implementation of RDDs that makes it a lot easier for python developers to work with the data Dataframes are tabular RDDs that support many features and functions that python developers have learned to appreciate in pandas They have many methods and properties that show the tabular data closer to how people are used to using in with an RDBMS or Excel Programming with PySpark: DataFrames
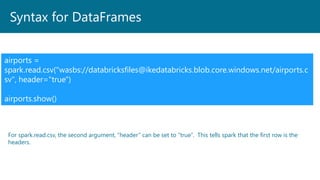
- 44. Syntax for DataFrames airports = spark.read.csv("wasbs://databricksfiles@ikedatabricks.blob.core.windows.net/airports.c sv", header="true") airports.show() For spark.read.csv, the second argument, “header” can be set to “true”. This tells spark that the first row is the headers.
- 45. Creates a new DataFrame from the previous one with an additional column. Adds “1” to the value. Add a column to a DataFrame df = df.withColumn("newCol", df.oldCol + 1)
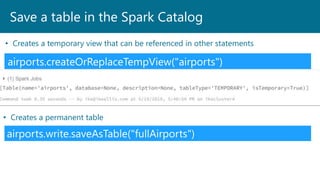
- 46. Save a table in the Spark Catalog airports.createOrReplaceTempView("airports") • Creates a temporary view that can be referenced in other statements airports.write.saveAsTable("fullAirports") • Creates a permanent table
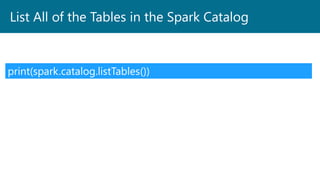
- 47. List All of the Tables in the Spark Catalog print(spark.catalog.listTables())
- 48. Query a DataFrame # Don't change this query query = "FROM airports SELECT * LIMIT 10" # Get the first 10 rows of flights airports10 = spark.sql(query) # Show the results airports10.show()
- 49. Explain Plan # Don't change this query query = "FROM airports SELECT * LIMIT 10" # Get the first 10 rows of flights airports10 = spark.sql(query).explain() • Read from bottom to top • Shows the steps to recreate the data frame • Shows what the driver will do when an action is called • Don’t worry too much about understanding everything they can just be helpful tools for debugging and improving your knowledge as you progress with Spark.
- 50. Reference a query string airportsInOregon = airports.filter(“state == ‘OR’") Reference the DataFrame airportsInOregon = airports.filter(airports.state == ‘OR’) Notice there is no string for the entire clause Two of the Ways to Filter
- 51. Bonus way to FILTER # Define first filter filterA = flights.origin == "SEA" # Define second filter filterB = flights.dest == "PDX" # Filter the data, first by filterA then by filterB selected2 = temp.filter(filterA).filter(filterB)
- 52. Same as the filter. Use a string # Select the first set of columns selected1 = airports.select(“faa", “long", “lat") Or use the DataFrame # Select the second set of columns temp = airports.select(airports.faa, airports.long, airports.lat) Two of the Ways to SELECT Columns
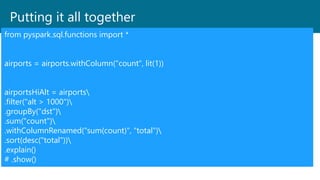
- 53. Putting it all together from pyspark.sql.functions import * airports = airports.withColumn("count", lit(1)) airportsHiAlt = airports .filter("alt > 1000") .groupBy("dst") .sum("count") .withColumnRenamed("sum(count)", "total") .sort(desc("total")) .explain() # .show()
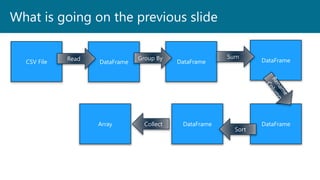
- 54. What is going on the previous slide CSV File DataFrame DataFrame DataFrame DataFrameDataFrame Read Group By Sum Sort Array Collect
- 55. Ike Ellis @ike_ellis Crafting Bytes We’re hiring a Data Experts! Microsoft MVP Chairperson of the San Diego TIG Book co-author – Developing Azure Solutions Upcoming course on Azure Databricks www.craftingbytes.com www.ikeellis.com Summary
- 56. Questions?
- 57. Coming up next… Evaluating Cloud Products for Data Warehousing Ginger Grant
- 58. Thank you for attending @sqlpass #sqlpass @PASScommunity Learn more from Ike @yourhandle email@company.com
Editor's Notes
- #2: [Moderator Part] Hello and welcome everyone to this 24 Hours of PASS: Summit Preview 2019! We’re excited you could join us today for Ike Ellis’s session, Azure Databricks is Easier than you Think. This 24 Hours of PASSconsists of 24 consecutive live webinars, delivered by expert speakers from the PASS community. The sessions will be recorded and posted online after the event. You will receive an email letting you know when these become available. My name is Rayees Khan [you can say a bit about yourself here if you’d like] I have a few introductory slides before I hand over the reins to Ike. [move to next slide]
- #3: [Moderator Part] If you require technical assistance please type your request into the question pane located on the right side of your screen and someone will assist you. This question pane is also where you may ask any questions throughout the presentation. Feel free to enter your questions at any time and once we get to the Q&A portion of the session, I’ll read your questions aloud to Ike. You are able to zoom in on the presentation content by using the zoom button located on the top of the presentation window. Please note that there will be a short evaluation at the end of the session, which will pop-up after the webinar ends in your web browser. Your feedback is really important to us for future events, so please take a moment to complete this. [Note to Rayees Khan: You need to determine which questions are the most relevant and ask them out loud to the presenter]. [move to next slide]
- #4: [Moderator Part] Our next scheduled PASS Marathon event is focused on Career Development and will take place on October 8th. Watch your inbox for an email when registration opens. Also, PASS Summit 2019 will be happening on November 5th in Seattle Washington. Head over to PASSsummit.com and register today! [move to next slide]
- #5: [Moderator Part] This 24 Hours of PASS session is presented by Ike Ellis. Ike is a Senior Data Architect and partner for Crafting Bytes. He has been a Microsoft Data Platform MVP since 2011. He co-authored the book "Developing Azure Solutions," now in its second edition. He is a popular speaker at SQLBits, PASS Summit, and SQL in the City. He has also written courses on SQL Server for developers, Power BI, SSRS, SSIS, and SSAS for Wintellect. [move to next slide]
- #6: And without further ado, here is Ike with Azure Databricks is Easier than you Think. {speaker begins} **[Speaker takes over]**
- #33: Show T-SQL Notebooks Margo story
- #55: Now there are seven steps that take us all the way back to the source data. You can see this in the explain plan on those DataFrames. Figure 2-10 shows the set of steps that we perform in “code.” The true execution plan (the one visible in explain) will differ from that shown in Figure 2-10 because of optimizations in the physical execution; however, the llustration is as good of a starting point as any. This execution plan is a directed acyclic graph (DAG) of transformations, each resulting in a new immutable DataFrame, on which we call an action to generate a result. Figure 2-10. The entire DataFrame transformation flow The first step is to read in the data. We defined the DataFrame previously but, as a reminder, Spark does not actually read it in until an action is called on that DataFrame or one derived from the original DataFrame. The second step is our grouping; technically when we call groupBy, we end up with a RelationalGroupedDataset, which is a fancy name for a DataFrame that has a grouping specified but needs the user to specify an aggregation before it can be queried further. We basically specified that we’re going to be grouping by a key (or set of keys) and that now we’re going to perform an aggregation over each one of those keys. Therefore, the third step is to specify the aggregation. Let’s use the sum aggregation method. This takes as input a column expression or, simply, a column name. The result of the sum method call is a new DataFrame. You’ll see that it has a new schema but that it does know the type of each column. It’s important to reinforce (again!) that no computation has been performed. This is simply another transformation that we’ve expressed, and Spark is simply able to trace our type information through it. The fourth step is a simple renaming. We use the withColumnRenamed method that takes two arguments, the original column name and the new column name. Of course, this doesn’t perform computation: this is just another transformation! The fifth step sorts the data such that if we were to take results off of the top of the DataFrame, they would have the largest values in the destination_total column. You likely noticed that we had to import a function to do this, the desc function. You might also have noticed that desc does not return a string but a Column. In general, many DataFrame methods will accept strings (as column names) or Column types or expressions. Columns and expressions are actually the exact same thing.
- #57: [Moderator to Address questions in order of relevance] [move to next slide] Coming up next…
- #58: Stay tuned for our next session, Evaluating Cloud Products for Data Warehousing with Ginger Grant. [move to next slide]
- #59: Thank you all for attending! [move to next slide]
- #60: This is 24 Hours of PASS [END]