








































Cloud computing and distributed systems.
- 1. Chapter 3 – Parallel & Distributed Systems
- 2. Contents 1. Cloud computing and distributed systems. 2. Parallel processing and distributed computing. 3. Parallel computer architecture. 4. SIMD architectures 5. Graphics processing units. 6. Speed-up and Amdahl’s Law. 7. Multicore processor speed up. 8. Distributed systems. 9. Modularity. 10. Layering. 11. Virtualization; layering and virtualization. 12. Per-to-peer systems. 2
- 3. Cloud computing and distributed systems Cloud computing is intimately tied to parallel and distributed processing. Parallel and distributed computing required major advances in several areas including, algorithms, programming languages and environments, performance monitoring, computer architecture, interconnection networks, and, last but not least, solid state technologies. The interconnection fabric was critical for the performance of parallel and distributed systems. Many cloud applications use a number of instances running concurrently. Transaction processing systems including web-based services represent a large class of applications hosted by computing clouds. Such applications run multiple instances of the service and require reliable and an in-order delivery of messages. 3
- 4. The path to cloud computing Cloud computing is based on ideas and the experience accumulated in many years of research in parallel and distributed systems. Cloud applications are based on the client-server paradigm with a relatively simple software, a thin-client, running on the user's machine, while the computations are carried out on the cloud. Concurrency is important; many cloud applications are data-intensive and use a number of instances which run concurrently. Checkpoint-restart procedures are used as many cloud computations run for extended periods of time on multiple servers. Checkpoints are taken periodically in anticipation of the need to restart a process when one or more systems fail. Communication is at the heart of cloud computing. Communication protocols which support coordination of distributed processes travel through noisy and unreliable communication channels which may lose messages or deliver duplicate, distorted, or out of order messages. 4
- 5. Parallel processing and distributed computing Parallel processing and distributed computing allow us to solve large problems by splitting them into smaller ones and solving them concurrently. Parallel processing refers to concurrent execution on a system with a large number of processors. Distributed computing means concurrent execution on multiple systems, often located at different sites. Distributed computing could only be efficient for coarse-grained parallel applications when concurrent activities seldom communicate with one another. Metrics such as execution time, speedup, and processor utilization characterize how efficiently a parallel or distributed system can process a particular application 5
- 6. Data parallelism versus task parallelism Data parallelism input data of an application is distributed to multiple processors/cores running concurrently. SIMD – Same Program Multiple Data; example, converting a large number of images in from one format to another – given 109 images batches of 106 images can be processed concurrently by 103 processors for a speedup of 1,000. Embarrassingly parallel applications Map Reduce - MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster. A MapReduce program is composed of a map procedure, which performs filtering and sorting, and a reduce method, which performs a summary operation. Task parallelism tasks are distributed to multiple processors; example – data from different sensors providing images, sounds, data can be processed concurrently by different programs each one tasks to identify specific anomalies. 6
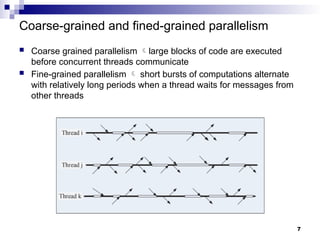
- 7. Coarse-grained and fined-grained parallelism Coarse grained parallelism large blocks of code are executed before concurrent threads communicate Fine-grained parallelism short bursts of computations alternate with relatively long periods when a thread waits for messages from other threads 7
- 8. Control flow and data-flow architecture Control flow architecture Pioneered by John von Neumann. Dominant processor architecture. The implementation of processor control flow is straightforward, a program counter determines the next instruction to be loaded into the instruction register and then executed. The execution is strictly sequential, until a branch is encountered. Data flow architecture - operations are carried out at the time when their input becomes available. Widely used by network routers, digital signal processors, and other special-purpose systems. The lack of locality, the inefficient use of cache, and ineffective pipelining are most likely some of the reasons why data flow general-purpose processors are not as popular as control flow processor. 8
- 9. Control flow and data-flow architecture (Cont’d) Data flow is emulated by von Neumann processors for dynamic instruction scheduling. Reservation stations to hold instructions waiting for their input to become available and the register renaming for out-of-order instruction execution. Some of the systems discussed in the class apply the data flow model for task scheduling on large clusters. 9
- 10. 10
- 11. Parallel computer architecture Bit level parallelism. The number of bits processed per clock cycle, often called a word size, has increased gradually from 4-bit, to 8-bit, 16-bit, 32-bit, and to 64-bit. This has reduced the number of instructions required to process larger size operands and allowed a significant performance improvement. During this evolutionary process the number of address bits have also increased allowing instructions to reference a larger address space. Instruction-level parallelism. Today's computers use multi-stage processing pipelines to speed up execution. Data parallelism or loop parallelism. The program loops can be processed in parallel. Task parallelism. The problem can be decomposed into tasks that can be carried out concurrently. For example, SPMD. Note that data dependencies cause different flows of control in individual tasks. 11
- 12. Classification of computer architectures Michael Flynn’s classification of computer architectures is based on the number of concurrent control/instruction and data streams: SISD (Single Instruction Single Data) – scalar architecture with one processor/core. SIMD (Single Instruction, Multiple Data) - supports vector processing. When a SIMD instruction is issued, the operations on individual vector components are carried out concurrently. MIMD (Multiple Instructions, Multiple Data) - a system with several processors and/or cores that function asynchronously and independently; at any time, different processors/cores may be executing different instructions on different data. We distinguish several types of systems: Uniform Memory Access (UMA). Cache Only Memory Access (COMA). Non-Uniform Memory Access (NUMA). 12
- 13. Pipelining Pipelining - splitting an instruction into a sequence of steps that can be executed concurrently by different circuitry on the chip. A basic pipeline of a RISC (Reduced Instruction Set Computing) architecture consists of five stages. The number of pipeline stages in different RISC processors varies. For example, ARM7 and earlier implementations of ARM processors have a three stage pipeline, fetch, decode, and execute. Higher performance designs, such as the ARM9, have deeper pipelines: Cortex-A8 pipeline has thirteen stages. A superscalar processor executes more than one instruction per clock cycle. A Complex Instruction Set Computer (CISC) architecture could have a much large number of pipelines stages, e.g., an Intel Pentium 4 processor has a 35-stage pipeline. 13
- 14. 14
- 15. Hazards – side effects of pipelining Instances when unchecked pipelining would produce incorrect results. Data hazards: Read after Write (RAW) occurs when an instruction operates with data in register that is being modified by a previous instruction. Write after Read (WAR) occurs when an instruction modifies data in a register being used by a previous instruction. Write after Write (WAW) occurs when two instructions in a sequence attempt to modify the data in the same register and the sequential execution order is violated. Structural hazards - the circuits implementing different hardware functions are needed by two or more instructions at the same time. E.g., a single memory unit is accessed during the instruction fetch stage where the instruction is retrieved from memory, and during the memory stage where data is written and/or read from memory. Control hazards - due to conditional branches. The processor will not know the outcome of the branch when it needs to insert a new instruction into the pipeline, normally during the fetch stage. 15
- 16. Pipeline requirements, stalls, and scheduling The architecture should: Preserve exception behavior, any change in instruction order must not change the order in which exceptions are raised, to ensure program correctness. Preserve instruction flow, the flow of data between instructions that produce results and consume them. Pipeline stall - delay in the execution of an instruction in an instruction pipeline in order to resolve a hazard. Such stalls could drastically affect the performance. Pipeline scheduling - separates dependent instruction from the source instruction by the pipeline latency of the source instruction. Its effect is to reduce the number of stalls. 16
- 17. Dynamic instruction scheduling Reduces the number of pipeline stalls, but adds to circuit complexity. Register renaming is sometimes supported by reservation stations. A reservation station fetches and buffers an operand as soon as it becomes available. A pending instruction designates the reservation station it will send its output to. A reservation station stores the following information: the instruction; buffered operand values (when available); and the id of the reservation station number providing the operand values. 17
- 18. SIMD architectures Flavors of SIMD architectures Vector architectures. SIMD extensions for mobile systems and multimedia applications. Graphics Processing Units (GPUs). Advantages: Exploit a significant level of data-parallelism. Enterprise applications in data mining and multimedia applications, applications in computational science and engineering using linear algebra benefit the most. Allow mobile device to exploit parallelism for media-oriented image and sound processing using SIMD extensions of ISA Are more energy efficient than MIMD architecture. Only one instruction is fetched for multiple data operations, rather than fetching one instruction per operation. Higher potential speedup than MIMD architectures. SIMD potential speedup could be twice as large as that of MIMD. Allows developers to continue thinking sequentially. 18
- 19. Vector architectures Vector registers holding as many as 64 or 128 vector elements. Vector functional units carry out arithmetic and logic operations using data from vector registers. Vector load-store units are pipelined, hide memory latency, and leverage memory bandwidth. The memory system spreads access to multiple memory banks which can be addressed independently. Vector length registers support handling of vectors whose length is not a multiple of the length of the physical vector registers. Vector mask registers disable/select vector elements and are used by conditional statements. Gather operations take an index vector and fetch vector elements at the addresses given by adding a base address to the offsets given by the index vector. A dense vector is loaded in a vector register. Scatter operations are the reverse of gather. 19
- 20. SIMD extensions for multimedia application Augment an existing instruction set of a scalar processor with a set of vector instructions. Advantages over vector architecture: Low cost to add circuitry to an existing ALU. Little extra state is added thus, the extensions have little impact on context-switching. Need little extra memory bandwidth. Do not pose additional complications to the virtual memory management for cross-page access and page-fault handling. Multimedia applications often run on mobile devices and operate on narrower data types than the native word size. E.g., graphics applications use 3 x 8 bits for colors and one 8-bit for transparency; audio applications use 8, 16, or 24-bit samples. 20
- 21. Extensions to Intel Architecture MMX introduced in 1996 Intel introduced MMX; supports eight 8-bit, or four 16-bit integer operations. SSE (1999 - 2004). The SSEs operate on eight 8-bit integers, four 32-bit or two 64-bit integer or floating-point operations. AVX (Advanced Vector Extensions) introduced in 2010 operates on four 64-bit either integer or floating-point operations. AVX family of Intel processors: Sandy Bridge, Ivy Bridge, Haswell, Broadwell, Skylake, and its follower, the Babylake. 21
- 23. Graphics processing units (GPUs) Real-time graphics with vectors of two, three, or four dimensions led to the development of GPUs. Also used in embedded systems, mobile phones, personal computers, workstations, and game consoles. GPU processing is based on a heterogeneous execution model with a CPU acting as the host connected with a GPU, called the device. Steps of a typical execution: CPU copies the input data from the main memory to the GPU memory. CPU instructs the GPU to start processing using the executable in the GPU memory. GPU uses multiple cores to execute the parallel code. When done the GPU copies the result back to the main memory. 23
- 24. GPUs organization and threads A GPU has multiple multithreaded SIMD processors. The current- generation of GPUs, e.g., Fermi of NVIDIA, have 7 to 15 multithreaded SIMD processors. A multithreaded SIMD processor has several wide & shallow SIMD lanes. For example, an NVIDIA GPU has 32,768 registers divided among the 16 physical SIMD lanes; each lane has 2,048 registers. Single-Instruction-Multiple-Thread (SIMT) is the GPU programming model. All forms of GPU parallelism are unified as CUDA threads in the SIMT model. CUDA, a C-like programming language developed by NVIDIA. A thread is associated with each data element. 24
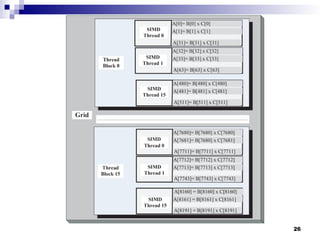
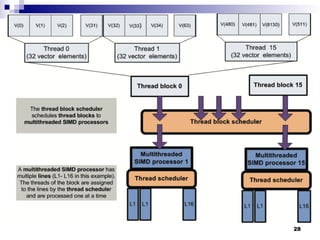
- 25. Grid, blocks, and threads Example Grid with 8192 components of vector A. 16 blocks with 512 vector components each. A bloc has 6 threads. A thread operates on 32 components of vector A$. 25
- 26. 26
- 27. GPU scheduling Multi-level scheduling Thread block scheduler assigns thread blocks to multithreaded SIMD processors. Thread scheduler running on each multithreaded SIMD processor assigns threads to the SIMD lanes of multithreaded processors. 27
- 28. 28
- 29. Speed-up and Amdahl’s Law Parallel hardware and software systems allow us to: Solve problems demanding resources not available on a single system. Reduce the time required to obtain a solution. The speed-up S measures the effectiveness of parallelization: S(N) = T(1) / T(N) T(1) the execution time of the sequential computation. T(N) the execution time when N parallel computations are executed. Amdahl's Law: if α is the fraction of running time a sequential program spends on non-parallelizable segments of the computation then S = 1/ α Gustafson's Law: the scaled speed-up with N parallel processes S(N) = N – α( N-1) 29
- 30. Multicore Processor Speedup We now live in the age of multicore processors brought about by the limitations imposed on solid state devices by the laws of physics. There are alternative designs of multicore processors: The cores can be identical or different from one another, there could be a few powerful cores or a larger number of less powerful cores. More cores will lead to high speedup of highly parallel applications, a powerful core will favor highly sequential applications The design space of multicore processors should be driven by cost- performance considerations. The cost of a multicore processor depends on the number of cores and the complexity, ergo, the power of individual cores. Cost-effective design the speedup achieved exceeds the cost up. Cost up multicore processor cost divided by the single-core processor cost. 30
- 31. Quantifying multicore design alternatives Basic Core Equivalent (BCE) quantifies resources of individual cores. A symmetric core processor may have n BCEs with r resources each. Alternatively, n x r resources may be distributed unevenly in an asymmetric core processor. The speedup of asymmetric multicore processors is always larger and, could be significantly larger than the speedup of symmetric core processors. For example, the largest speedup when f = 0.975 and n = 1024 is achieved for a configuration with one 345-BCE core and 679 1-BCE cores. Increasing the power of individual cores is beneficial even for symmetric core processors. For example, when f=0.975 and n=256 the maximum speedup occurs for seven 1-BCE cores. f is the fraction of an application that is parallelizable. 31
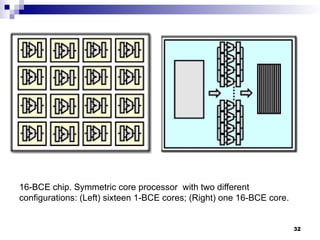
- 32. 16-BCE chip. Symmetric core processor with two different configurations: (Left) sixteen 1-BCE cores; (Right) one 16-BCE core. 32
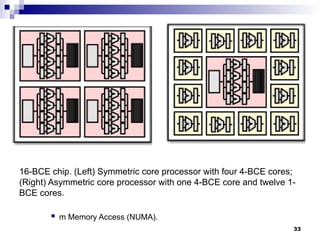
- 33. 16-BCE chip. (Left) Symmetric core processor with four 4-BCE cores; (Right) Asymmetric core processor with one 4-BCE core and twelve 1- BCE cores. m Memory Access (NUMA). 33
- 34. Distributed systems Collection of autonomous computers, connected through a network operating under the control and distribution software. Middleware software enabling individual systems to coordinate their activities and to share system resources. Main characteristics of distributed systems: The users perceive the system as a single, integrated computing facility. The components are autonomous. Scheduling and other resource management and security policies are implemented by each system. There are multiple points of control and multiple points of failure. The resources may not be accessible at all times. Can be scaled by adding additional resources. Can be designed to maintain availability even at low levels of hardware/software/network reliability. 34
- 35. Distributed systems - desirable properties Access transparency - local and remote information objects are accessed using identical operations. Location transparency - information objects are accessed without knowledge of their location. Concurrency transparency - several processes run concurrently using shared information objects without interference among them. Replication transparency - multiple instances of information objects increase reliability without the knowledge of users or applications. Failure transparency - the concealment of faults. Migration transparency - the information objects in the system are moved without affecting the operation performed on them. Performance transparency - the system can be reconfigured based on the load and quality of service requirements. Scaling transparency - the system and the applications can scale without a change in the system structure and without affecting the applications. 35
- 36. Modularity Modularity, layering, and hierarchy are means to cope with the complexity of a distributed application software. Software modularity, the separation of a function into independent, interchangeable modules requires well-defined interfaces specifying the elements provided and supplied to a module. Requirement for modularity clearly define the interfaces between modules and enable the modules to work together. The steps involved in the transfer of the flow of control between the caller and the callee: The caller saves its state including the registers, the arguments, and the return address on the stack The callee loads the arguments from the stack, carries out the calculations and then transfers control back to the caller. The caller adjusts the stack, restores its registers, and continues its processing. 36
- 37. Modular software design principles Information hiding the user of a module does not need to know anything about the internal mechanism of the module to make effective use of it. Invariant behavior the functional behavior of a module must be independent of the site or context from which it is invoked. Data generality the interface to a module must be capable of passing any data object an application may require. Secure arguments the interface to a module must not allow side- effects on arguments supplied to the interface. Recursive construction a program constructed from modules must be usable as a component in building larger programs/modules System resource management resource management for program modules must be performed by the computer system and not by individual program modules. 37
- 38. Soft modularity Soft modularity divide a program into modules which call each other and communicate using shared-memory or follow procedure call convention. Hides module implementation details. Once the interfaces of the modules are defined, the modules can be developed independently. A module can be replaced with a more elaborate, or with a more efficient one, as long as its interfaces with the other modules are not changed. The modules can be written using different programming languages and can be tested independently. Challenges: Increases the difficulty of debugging; for example, a call to a module with an infinite loop will never return. There could be naming conflicts and wrong context specifications. The caller and the callee are in the same address space and may misuse the stack, e.g., the callee may use registers that the caller has not saved on the stack, and so on. 38
- 39. Enforced modularity; the client-server paradigm Modules are forced to interact only by sending and receiving messages. More robust design, Clients and servers are independent modules and may fail separately. Does not allow errors to propagate. Servers are stateless, they do not have to maintain state information. A server may fail and then come back up without the clients being affected, or even noticing the failure of the server. Enforced modularity makes an attack less likely because it is difficult for an intruder to guess the format of the messages or the sequence numbers of segments, when messages are transported by TCP. Often based on RPCs. 39
- 40. Remote procedure calls (RPCs) Introduced in early 1970s by Bruce Nelson and used for the first time at PARC. Reduce fate sharing between caller and the callee. RPCs take longer than local calls due to communication delays. RPC semantics At least once a message is resent several times and an answer is expected. The server may end up executing a request more than once, but an answer may never be received. Suitable for operation free of side-effects At most once a message is acted upon at most once. The sender sets up a timeout for receiving the response. When the timeout expires an error code is delivered to the caller. Requires the sender to keep a history of the time-stamps of all messages as messages may arrive out-of-order. Suitable for operations which have side effects Exactly once implements at most once semantics and requests an acknowledgment from server. 40
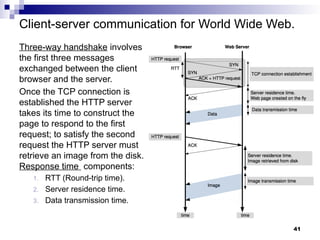
- 41. Client-server communication for World Wide Web. Three-way handshake involves the first three messages exchanged between the client browser and the server. Once the TCP connection is established the HTTP server takes its time to construct the page to respond to the first request; to satisfy the second request the HTTP server must retrieve an image from the disk. Response time components: 1. RTT (Round-trip time). 2. Server residence time. 3. Data transmission time. 41
- 42. Layering and hierarchy Layering demands modularity each layer fulfills a well-defined function. Communication patterns are more restrictive, a layer is expected to communicate only with the adjacent layers. This restriction reduces the system complexity and makes it easier to understand its behavior. Strictly enforced layering can prevent optimizations. For example, cross-layer communication in networking was proposed to allow wireless applications to take advantage of information available at the Media Access Control (MAC) sub-layer of the data link layer. There are systems where it is difficult to envision a layered organization because of the complexity of the interaction between the individual modules. Could a layered cloud architecture be designed that has practical implications for the future development of computing clouds? 42
- 43. Communication protocol layering Internet protocol stack: Physical layer accommodate divers physical communication channels carrying electromagnetic, optical, or acoustic signals . Data link layerHow address the problem to transport bits, not signals between two systems directly connected to one another by a communication channel. Network layer packets carying bits have to traverse a chain of intermediate nodes from a source to the destination; the concern is how to forward the packets from one intermediate node to the next. Transport layer the source and the recipient of packets are outside the network this layer guarantees delivery from source to destination. Application layer data sent and received by the hosts at the network periphery has a meaning only in the context of an application. 43
- 44. Virtualization; layering and virtualization Virtualization abstracts the underlying physical resources of a system and simplifies its use, isolates users from one another, and supports replication which increases system elasticity and reliability. Virtualization simulates the interface to a physical object: Multiplexing create multiple virtual objects from one instance of a physical object. E.g., a processor is multiplexed among a number of processes or threads. Aggregation create one virtual object from multiple physical objects. E.g., a number of physical disks are aggregated into a RAID disk. Emulation construct a virtual object from a different type of a physical object. E.g., a physical disk emulates Random Access Memory. Multiplexing and emulation E.g., virtual memory with paging multiplexes real memory and disk and a virtual address emulates a real address; the TCP protocol emulates a reliable bit pipe and multiplexes a physical communication channel and a processor. 44
- 45. Virtualization and cloud computing Virtualization is a critical aspect of cloud computing, equally important for providers and consumers of cloud services for several reasons: System security it allows isolation of services running on the same hardware. Performance isolation allows developers to optimize applications and cloud service providers to exploit multi-tenancy. Performance and reliability it allows applications to migrate from one platform to another. Facilitates development and management of services offered by a provider. A hypervisor runs on the physical hardware and exports hardware- level abstractions to one or more guest operating systems. A guest OS interacts with the virtual hardware in the same manner it would interact with the physical hardware, but under the watchful eye of the hypervisor which traps all privileged operations and mediates the interactions of the guest OS with the hardware. 45
- 46. Peer-to-peer systems (P2P) P2P represents a significant departure from the client-server model and have several desirable properties: Require a minimally dedicated infrastructure, as resources are contributed by the participating systems. Highly decentralized. Scalable, individual nodes are not required to be aware of global state. Are resilient to faults and attacks, as few of their elements are critical for the delivery of service and the abundance of resources can support a high degree of replication. Individual nodes do not require excessive network bandwidth as servers used by client-server model do. The systems are shielded from censorship due to the dynamic and often unstructured system architecture. Undesirable properties: Decentralization raises the question if P2P systems can be managed effectively and provide the security required by various applications. Shielding from censorship makes them a fertile ground for illegal activities. 46
- 47. Resource sharing in P2P systems This distributed computing model promotes low-cost access to storage and CPU cycles provided by participant systems. Resources are located in different administrative domains. P2P systems are self-organizing and decentralized, while the servers in a cloud are in a single administrative domain and have a central management. Napster, a music-sharing system, developed in late 1990s gave participants access to storage distributed over the network. The first volunteer-based scientific computing, SETI@home, used free cycles of participating systems to carry out compute-intensive tasks. 47
- 48. Organization of P2P systems Regardless of the architecture, P2P systems are built around an overlay network, a virtual network superimposed over the real network. Each node maintains a table of overlay links connecting it with other nodes of this virtual network, each node is identified by its IP addresses. Two types of overlay networks, unstructured and structured, are used. Random walks starting from a few bootstrap nodes are usually used by systems desiring to join an unstructured overlay. Each node of a structured overlay has a unique key which determines its position in the structure; the keys are selected to guarantee a uniform distribution in a very large name space. Structured overlay networks use key-based routing (KBR); given a starting node v0 and a key k, the function KBR(v0,k) returns the path in the graph from v0 to the vertex with key k. Epidemic algorithms are often used by unstructured overlays to disseminate network topology. 48
- 49. Examples of P2P systems Skype, a voice over IP telephony service allows close to 700 million registered users from many countries around the globe to communicate using a proprietary voice-over-IP protocol. Data streaming applications such as Cool Streaming BBC's online video service, Content distribution networks such as CoDeeN. Volunteer computing applications based on the BOINC (Berkeley Open Infrastructure for Networking Computing) platform. 49