



























![Standalone (Scala)
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your
system
val conf = new SparkConf().setAppName("Simple Application")
.setMaster(“local")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}](https://image.slidesharecdn.com/bigdata-vahidamiri-tabriz-13960226-datastack-170526125454/85/Big-data-vahidamiri-tabriz-13960226-datastack-ir-42-320.jpg)
![Standalone (Java)
public class SimpleApp {
public static void main(String[] args) {
String logFile = “LOGFILES_ADDRESS";
SparkConf conf = new SparkConf().setAppName("Simple Application").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> logData = sc.textFile(logFile);
long numAs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("a"); }
}).count();
long numBs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("b"); }
}).count();
System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
}
}](https://image.slidesharecdn.com/bigdata-vahidamiri-tabriz-13960226-datastack-170526125454/85/Big-data-vahidamiri-tabriz-13960226-datastack-ir-43-320.jpg)

Big data vahidamiri-tabriz-13960226-datastack.ir
- 1. ،مفاهیم داده؛ کالن هاحل راه و هاچالش VAHID AMIRI VAHIDAMIRY.IR VAHID.AMIRY@GMAIL.COM @DATASTACK های داده پردازش و توزیعی محاسبات ملی کنفرانس سومینبزرگ تبریز اردیبهشت96
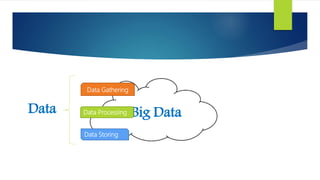
- 2. Big DataData Data Processing Data Gathering Data Storing
- 4. Big Data Definition No single standard definition… “Big Data” is data whose scale, diversity, and complexity require new architecture, techniques, algorithms, and analytics to manage it and extract value and hidden knowledge from it…
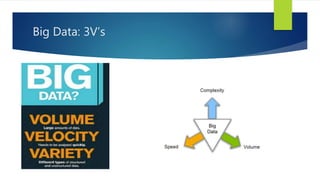
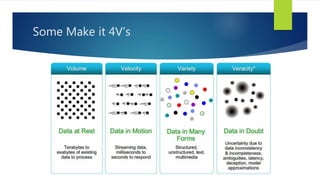
- 6. Some Make it 4V’s
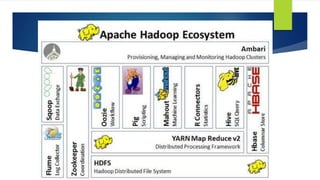
- 9. Hadoop is a software framework for distributed processing of large datasets across large clusters of computers Hadoop implements Google’s MapReduce, using HDFS MapReduce divides applications into many small blocks of work. HDFS creates multiple replicas of data blocks for reliability, placing them on compute nodes around the cluster Hadoop
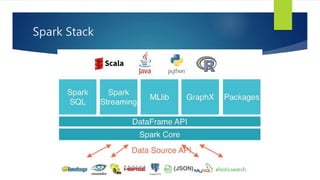
- 11. Spark Stack
- 12. More than just the Elephant in the room Over 120+ types of NoSQL databases So many NoSQL options
- 13. Extend the Scope of RDBMS Caching Master/Slave Table Partitioning Federated Tables Sharding NoSql Relational database (RDBMS) technology Has not fundamentally changed in over 40 years Default choice for holding data behind many web apps Handling more users means adding a bigger server
- 14. RDBMS with Extended Functionality Vs. Systems Built from Scratch with Scalability in Mind NoSQL Movement
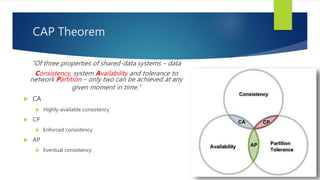
- 15. CAP Theorem “Of three properties of shared-data systems – data Consistency, system Availability and tolerance to network Partition – only two can be achieved at any given moment in time.”
- 16. “Of three properties of shared-data systems – data Consistency, system Availability and tolerance to network Partition – only two can be achieved at any given moment in time.” CA Highly-available consistency CP Enforced consistency AP Eventual consistency CAP Theorem
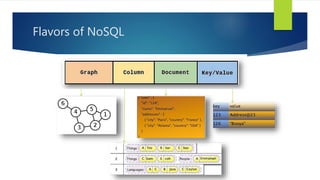
- 17. Flavors of NoSQL
- 18. Schema-less State (Persistent or Volatile) Example: Redis Amazon DynamoDB Key / Value Database
- 19. Wide, sparse column sets Schema-light Examples: Cassandra HBase BigTable GAE HR DS Column Database
- 20. Use for data that is document-oriented (collection of JSON documents) w/semi structured data Encodings include XML, YAML, JSON & BSON binary forms PDF, Microsoft Office documents -- Word, Excel…) Examples: MongoDB, CouchDB Document Database
- 21. Graph Database Use for data with a lot of many-to-many relationships when your primary objective is quickly finding connections, patterns and relationships between the objects within lots of data Examples: Neo4J, FreeBase (Google)
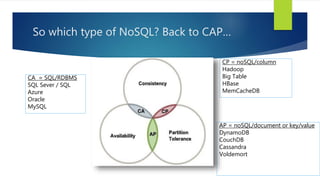
- 22. So which type of NoSQL? Back to CAP… CP = noSQL/column Hadoop Big Table HBase MemCacheDB AP = noSQL/document or key/value DynamoDB CouchDB Cassandra Voldemort CA = SQL/RDBMS SQL Sever / SQL Azure Oracle MySQL
- 25. About Apache Spark Fast and general purpose cluster computing system 10x (on disk) - 100x (In-Memory) faster Most popular for running Iterative Machine Learning Algorithms. Provides high level APIs in Java Scala Python R http://spark.apache.org/
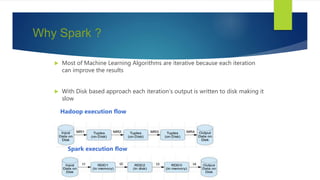
- 26. Why Spark ? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration’s output is written to disk making it slow Hadoop execution flow Spark execution flow
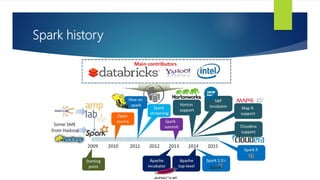
- 27. Spark history
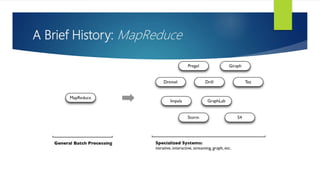
- 28. A Brief History: MapReduce MapReduce use cases showed two major limitations: difficultly of programming directly in MR performance bottlenecks, or batch not fitting the use cases
- 29. A Brief History: MapReduce
- 30. A Brief History: Spark Some key points about Spark: handles batch, interactive, and real-time within a single framework native integration with Java, Python, Scala programming at a higher level of abstraction more general: map/reduce is just one set of supported constructs
- 31. Spark Stack Spark SQL For SQL and unstructured data processing MLib Machine Learning Algorithms GraphX Graph Processing Spark Streaming stream processing of live data streams
- 32. Cluster Deployment Standalone Deploy Mode simplest way to deploy Spark on a private cluster Amazon EC2 EC2 scripts are available Very quick launching a new cluster Apache Mesos Hadoop YARN
- 33. Which Language Should I Use? Standalone programs can be written in any, but console is only Python & Scala Python developers: can stay with Python for both Java developers: consider using Scala for console (to learn the API) Performance: Java / Scala will be faster (statically typed), but Python can do well for numerical work with NumPy
- 34. RDD Resilient Distributed Datasets (RDD) are the primary abstraction in Spark – a fault-tolerant collection of elements that can be operated on in parallel
- 35. RDD two types of operations on RDDs: transformations and actions transformations are lazy (not computed immediately) the transformed RDD gets recomputed when an action is run on it (default) however, an RDD can be persisted into storage in memory or disk
- 36. Transformations Transformations create a new dataset from an existing one All transformations in Spark are lazy: they do not compute their results right away – instead they remember the transformations applied to some base dataset optimize the required calculations recover from lost data partitions
- 37. Transformations
- 38. Transformations
- 39. Actions
- 40. Actions
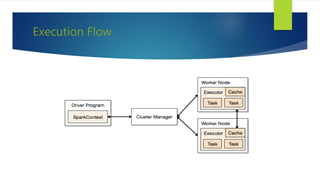
- 41. Execution Flow
- 42. Standalone (Scala) /* SimpleApp.scala */ import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object SimpleApp { def main(args: Array[String]) { val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system val conf = new SparkConf().setAppName("Simple Application") .setMaster(“local") val sc = new SparkContext(conf) val logData = sc.textFile(logFile, 2).cache() val numAs = logData.filter(line => line.contains("a")).count() val numBs = logData.filter(line => line.contains("b")).count() println("Lines with a: %s, Lines with b: %s".format(numAs, numBs)) } }
- 43. Standalone (Java) public class SimpleApp { public static void main(String[] args) { String logFile = “LOGFILES_ADDRESS"; SparkConf conf = new SparkConf().setAppName("Simple Application").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> logData = sc.textFile(logFile); long numAs = logData.filter(new Function<String, Boolean>() { public Boolean call(String s) { return s.contains("a"); } }).count(); long numBs = logData.filter(new Function<String, Boolean>() { public Boolean call(String s) { return s.contains("b"); } }).count(); System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs); } }