NoSQL databases
118 likes20,772 views

This document provides an overview and introduction to NoSQL databases. It discusses key-value stores like Dynamo and BigTable, which are distributed, scalable databases that sacrifice complex queries for availability and performance. It also explains column-oriented databases like Cassandra that scale to massive workloads. The document compares the CAP theorem and consistency models of these databases and provides examples of their architectures, data models, and operations.




































![CouchDB
• http://couchdb.apache.org/ , ~2005
• Schema-free, document oriented database
– Documents stored in JSON format (XML in old versions)
– B-tree storage engine
– MVCC model, no locking
– no joins, no PK/FK (UUIDs are auto assigned)
– Implemented in Erlang
• 1st version in C++, 2nd in Erlang and 500 times more scalable (source:
“Erlang Programming” by Cesarini & Thompson)
– Replication (incremental)
{
• Documents “name”: “Ontotext”,
“url”: “www.ontotext.com”
– UUID, version “employees”: 40
– Old versions retained “products”: [“OWLIM”, “KIM”, “LifeSKIM”, “JOCI”]
}
NoSQL Databases Mar 2010 #46](https://image.slidesharecdn.com/techwatch-nosql-100329073709-phpapp01/85/NoSQL-databases-46-320.jpg)








NoSQL databases
- 1. NoSQL Databases technology watch #2 Mar 2010
- 2. Contents • Introduction • Key-Value stores • Column stores • Document stores • Graph Databases • Benchmarks • RDF & NoSQL NoSQL Databases Mar 2010 #2
- 3. Contents Part I Introduction NoSQL Databases Mar 2010 #3
- 4. Why NoSQL? • Is NoSQL equal to “SQL “or to “Not Only SQL”? • ACID doesn’t scale well • Web apps have different needs (than the apps that RDBMS were designed for) – Low and predictable response time (latency) – Scalability & elasticity (at low cost!) – High availability – Flexible schemas / semi-structured data – Geographic distribution (multiple datacenters) • Web apps can (usually) do without – Transactions / strong consistency / integrity – Complex queries NoSQL Databases Mar 2010 #4
- 5. Some NoSQL use cases 1. Massive data volumes – Massively distributed architecture required to store the data – Google, Amazon, Yahoo, Facebook – 10-100K servers 2. Extreme query workload – Impossible to efficiently do joins at that scale with an RDBMS 3. Schema evolution – Schema flexibility (migration) is not trivial at large scale – Schema changes can be gradually introduced with NoSQL NoSQL Databases Mar 2010 #5
- 6. NoSQL pros/cons • Advantages – Massive scalability – High availability – Lower cost (than competitive solutions at that scale) – (usually) predictable elasticity – Schema flexibility, sparse & semi-structured data • Disadvantages – Limited query capabilities (so far) – Eventual consistency is not intuitive to program for • Makes client applications more complicated – No standardizatrion • Portability might be an issue – Insufficient access control NoSQL Databases Mar 2010 #6
- 7. CAP theorem • Requirements to distributed systems – Consistency – the system is in a consistent state after an operation • All clients see the same data • Strong consistency (ACID) vs. eventual consistency (BASE) – Availability – the system is “always on”, no downtime • Node failure tolerance – all clients can find some available replica • software/hardware upgrade tolerance – Partition tolerance – the system continues to function even when split into disconnected subsets (by a network disruption) • Not only for reads, but writes as well! • CAP Theorem (E. Brewer, N. Lynch) – You can satisfy at most 2 out of the 3 requirements NoSQL Databases Mar 2010 #7
- 8. CAP (2) • CA – Single site clusters (easier to ensure all nodes are always in contact) – e.g. 2PC – When a partition occurs, the system blocks • CP – Some data may be inaccessible (availability sacrificed), but the rest is still consistent/accurate – e.g. sharded database • AP – System is still available under partitioning, but some of the data returned my be inaccurate – e.g. DNS, caches, Master/Slave replication – Need some conflict resolution strategy NoSQL Databases Mar 2010 #8
- 9. … and also CAE • CAE trade-off (Amazon?) – Cost-efficiency – High Availability – Elasticity • Pick any two (Cost, Availability, Elasticity) – Cost Efficiency • By over-provisioning you get HA and E – High Availability • Just make the client wait when the system is overloaded (CE and E) – Elasticity • If you can predict your workload, you can provide HA + CE by booking the resources in advance • Everyone wants HA, so the challenge is providing E in a CE way NoSQL Databases Mar 2010 #9
- 10. NoSQL taxonomy • Key-Value stores – Simple K/V lookups (DHT) • Column stores – Each key is associated with many attributes (columns) – NoSQL column stores are actually hybrid row/column stores • Different from “pure” relational column stores! • Document stores – Store semi-structured documents (JSON) – Map/Reduce based materialisation, sorting, aggregation, etc. • Graph databases – Not exactly NoSQL… • can’t satisfy the requirements for High Availability and Scalability/Elasticity very well NoSQL Databases Mar 2010 #10
- 11. Contents Part II Key-Value stores PNUTS, Dynamo, Voldemort NoSQL Databases Mar 2010 #11
- 12. PNUTS • Yahoo, ~2008, part of the Y! Sherpa platform • Requirements – Scale out / elasticity – Geo-replication – High availability / Fault tolerance – Relaxed consistency • Simplified relational data model – Flexible schema – No Referential Integrity – No joins, aggregation, etc – Updates/deletes only by Primary Key – “Multiget” (retrieve many records by PKs) NoSQL Databases Mar 2010 #12
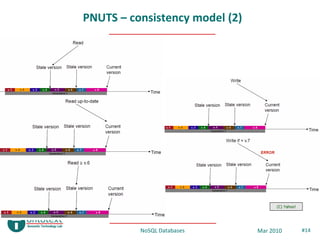
- 13. PNUTS – consistency model • Timeline consistency – In-between serializability and eventual consistency • All replicas apply updates for a record in the same order • but not necessarily at the same time (eventually) – One replica is always chosen as a Master (per record!) • adaptively changed for load re-balancing (usage pattern tracking!) • updates go only to the Master, then async propagation to other replicas / reads go to replicas or Master – Read consistency levels • Read any – may return a stale version of a record (any replica, fast) • Read critical (V) – return a newer (or the same) record version than V • Read latest – most recent version (goes to Master, slow) – Write consistency levels • Write • Test-and-set (V) – write only if the record version is the same as V (ensures serialization) NoSQL Databases Mar 2010 #13
- 14. PNUTS – consistency model (2) (C) Yahoo! NoSQL Databases Mar 2010 #14
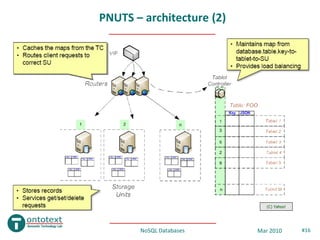
- 15. PNUTS - architecture • Regions – (usually) geographically distributed replicas (20+ datacenters) – Pub/Sub asynchronous replication (Tribble) • Tablets – Horizontal partitioning of the tables (keyspace) – One copy of a Tablet within each Region • Components – Routers • Cached copy of the interval mapping for tablets – Storage Units (SU) • Filesystem or MySQL – Tablet Controllers (TC) • Maintains interval mapping, tablet split, load re-balancing, etc NoSQL Databases Mar 2010 #15
- 16. PNUTS – architecture (2) (C) Yahoo! NoSQL Databases Mar 2010 #16
- 17. PNUTS – architecture (3) • Message Broker – Pub/Sub replication – Notification service (even for external apps) – Reliable logging – 1 broker per tablet, but subscriptions on the table level possible too • “Mastership” – Record master – updates, “read latest” – Tablet master – inserts & deletes • Query processing – Replica – “read any”, “read critical” – Master – updates, “read latest” – Scatter/Gather engine – range queries, table scans, multi-record updates NoSQL Databases Mar 2010 #17
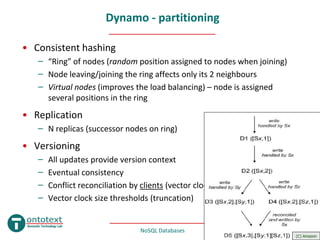
- 18. Dynamo • Amazon, ~2007 • P2P key-value store – Object versioning – Consistent hashing – Gossip – membership & failure detection – Quorum reads • Requirements & assumptions – Simple query model (unique keys, blobs, no schema, no multi-access) – Scale out (elasticity) – Eventual consistency (improved availability) – Decentralized & symmetric (P2P), heterogeneous (load distribution) – Low latency / high throughput – Internal service (no security model) NoSQL Databases Mar 2010 #18
- 19. Dynamo - partitioning • Consistent hashing – “Ring” of nodes (random position assigned to nodes when joining) – Node leaving/joining the ring affects only its 2 neighbours – Virtual nodes (improves the load balancing) – node is assigned several positions in the ring • Replication – N replicas (successor nodes on ring) • Versioning – All updates provide version context – Eventual consistency – Conflict reconciliation by clients (vector clocks) – Vector clock size thresholds (truncation) NoSQL Databases Mar 2010 #19 (C) Amazon
- 20. Dynamo – operations • Read/Write requests – Client sends a request to a random node, the node forwards it to the proper node (1st replica responsible for that partition – coordinator) – Coordinator will forward R/W requests to top N replicas • Consistency – Quorum protocol • R, W – minimum number of nodes that must participate in a Read/ Write operation (R+W > N) – Writes • Coordinator generates the version and the vector clock • Coordinator sends requests to N replicas, if W replicas confirm then OK – Reads • Coordinator sends requests to N replicas, if R replicas respond then OK • If different versions are returned then reconcile and write back the reconciled version (read repair) NoSQL Databases Mar 2010 #20
- 21. Dynamo – failure handling • “Hinted handoff” – Dynamo is “always writable” – If a replica node NR is down, the coordinator sends the write data to a new node NHH (with a hint that NR was the intended recipient) – Hinted writes are not readable, i.e. read quorum may still fail! – NHH will keep the data until NR is available again, then send the data version to NR and delete the local copy • “Anti-entropy” replica synchronisation – What if a hinted replica NHH fails before it can sync with NR? – Merkle trees • Pros – minimum data transfer (only the root node hash compared when in-sync), very fast location of out-of-sync keys (tree traversal) • Cons – trees need to be re-calculated when nodes join/leave the ring (keyspace partitioning changes) NoSQL Databases Mar 2010 #21
- 22. Dynamo – architecture • Bootstrapping & node removal – New node gets a position in the ring – Several re-balancing strategies • Partition split - the node responsible for that keyspace partition splits it and sends half the data to the new node • Fixed size partitions – one or more partitions are sent to the new node – Similar process when a node leaves the ring • Node components – Request handling & coordination – Membership & failure detection – Local persistence engine • MySQL • BerkleyDB • In-memory buffer + persistence NoSQL Databases Mar 2010 #22
- 23. Voldemort • http://project-voldemort.com/ • Distributed key-value store – Based on Dynamo • Originally developed by LinkedIn, now open source • Features – Simple data model (no joins or complex queries, no RI, …) – P2P – Scale-out / elastic • Consistent hashing of keyspace • Fixed partitions (no splits, but owner may change when re-balancing) – Eventual consistency / High Availability – Replication – Failure handling NoSQL Databases Mar 2010 #23
- 24. Voldemort & Dynamo • Similar to Dynamo – Consistent hashing – Versions & Vector clocks -> eventual consistency – R/W quorum (R+W>N) – Hinted handoff (failure handling) – Pluggable persistence engines • MySQL, BerkeleyDB, in-memory NoSQL Databases Mar 2010 #24
- 25. Contents Part III Column stores BigTable, HBase, Cassandra NoSQL Databases Mar 2010 #25
- 26. BigTable • Google, ~2006 • Sparse, distributed, persistent multidimensional sorted map • (row, column, timestamp) dimensions, value is string • Key features – Hybrid row/column store – Single master (stand-by replica) – Versioning – Compression (C) Google NoSQL Databases Mar 2010 #26
- 27. BigTable - data model • Row – Keys are arbitrary strings – Data is sorted by row key • Tablet – Row range is dynamically partitioned into tablets (sequence of rows) – Range scans are very efficient – Row keys should be chosen to improve locality of data access • Column, Column Family – Column keys are arbitrary strings, unlimited number of columns – Column keys can be grouped into families – Data in a CF is stored and compressed together (Locality Groups) – Access control on the CF level NoSQL Databases Mar 2010 #27
- 28. BigTable - data model (2) • Timestamps – Each cell has multiple versions – Can be manually assigned • Versioning – Automated garbage collection • Retain last N versions • Retain versions newer than TS • Architecture – Data stored on GFS – Relies on Chubby (distributed lock service, Paxos) – 1 Master server – thousands of Tablet servers NoSQL Databases Mar 2010 #28
- 29. BigTable - architecture • Master server – Assign tablets to Tablet Servers – Balance TS load – Garbage collection – Schema management – Client data does not move through the MS (directly through TS) – Tablet location not handled by MS • Tablet server (many) – thousands of tablets per TS – Manages Read / Write / Split of its tablets NoSQL Databases Mar 2010 #29
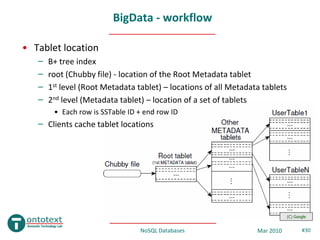
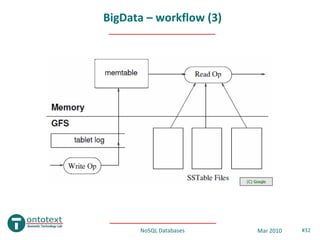
- 30. BigData - workflow • Tablet location – B+ tree index – root (Chubby file) - location of the Root Metadata tablet – 1st level (Root Metadata tablet) – locations of all Metadata tablets – 2nd level (Metadata tablet) – location of a set of tablets • Each row is SSTable ID + end row ID – Clients cache tablet locations (C) Google NoSQL Databases Mar 2010 #30
- 31. BigData – workflow (2) • Tablet access – SSTable – persistent, ordered immutable map from keys to values • Contains a sequence of blocks + block index • Compression at block level • 2 phase compression, 10:1 ratio (standard gzip up to 3:1) – Updates • 1st added to the redo log • Then to the in-memory buffer (memtable) • If memtable is full, then it is flushed into a new SSTable and emptied – Reads • Executed over the merged memtable and all SSTables (Bloom filters) • Merged view is very efficient (data is already sorted) • Bloom filters – probabilistic maps on whether a specific SSTable contains a specific cell (row, column), i.e. disk lookups are drastically reduced NoSQL Databases Mar 2010 #31
- 32. BigData – workflow (3) (C) Google NoSQL Databases Mar 2010 #32
- 33. BigData – workflow (4) • SSTable compactions – Minor compaction • Memtable flushed on disk into a new SSTable and emptied • When: memtable is full – Merging compaction • Merge the memtable and several SSTables into 1+ new SSTable(s) • Then, empty the memtable and delete the input SSTables • New SSTable(s) can still contain deletion info + deleted data (no purging) • When: number of SSTables limit reached – Major compaction • A merging compaction with exactly 1 output SSTable and all deleted data purged • When: regularly (background) NoSQL Databases Mar 2010 #33
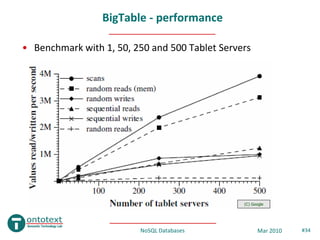
- 34. BigTable - performance • Benchmark with 1, 50, 250 and 500 Tablet Servers (C) Google NoSQL Databases Mar 2010 #34
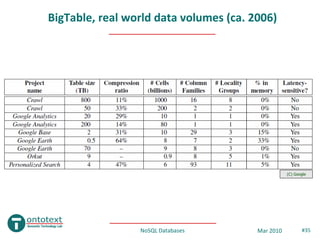
- 35. BigTable, real world data volumes (ca. 2006) (C) Google NoSQL Databases Mar 2010 #35
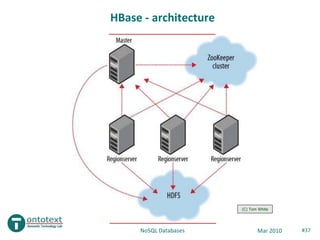
- 36. HBase • http://hadoop.apache.org/hbase • Developed by Powerset, now Apache • Based on BigTable – HDFS (GFS), ZooKeeper (Chubby) – Master Node (Master Server), Region Servers (Tablet Servers) – HStore (tablet), memcache (memtable), MapFile (SSTable) • Features – Data is stored sorted (no real indexes) – Automatic partitioning – Automatic re-balancing / re-partitioning – Fault tolerance (HDFS, 3 replicas) NoSQL Databases Mar 2010 #36
- 37. HBase - architecture (C) Tom White NoSQL Databases Mar 2010 #37
- 38. HBase - operations • Workflow – Hstore/tablet location (== BigTable) • clients talk to ZooKeeper • root metadata, metadata tables, client side caching, etc – Writes (== BigTable) • First added to the commit log, then to the memcache (memtable), eventually flushed to MapFile (SSTable) – Reads (== BigTable) • First read from memcache, if info is incomplete then read the MapFiles – Compactions (== BigTable) • APIs – Thrift – REST • GET | PUT | POST | DELETE <table>/<row>/<column>:<qualifier>/<timestamp> NoSQL Databases Mar 2010 #38
- 39. HBase – MapReduce jobs • Can be a source/sink for M/R jobs in Hadoop (C) ??? NoSQL Databases Mar 2010 #39
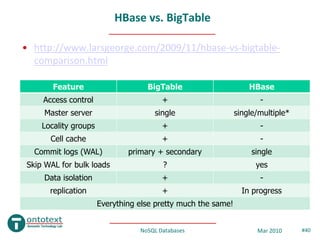
- 40. HBase vs. BigTable • http://www.larsgeorge.com/2009/11/hbase-vs-bigtable- comparison.html Feature BigTable HBase Access control + - Master server single single/multiple* Locality groups + - Cell cache + - Commit logs (WAL) primary + secondary single Skip WAL for bulk loads ? yes Data isolation + - replication + In progress Everything else pretty much the same! NoSQL Databases Mar 2010 #40
- 41. Cassandra • http://cassandra.apache.org/ • Developed by Facebook (inbox), now Apache – Facebook now developing its own version again • Based on Google BigTable (data model) and Amazon Dynamo (partitioning & consistency) • P2P – Every node is aware of all other nodes in the cluster • Design goals – High availability – Eventual consistency (improves HA) – Incremental scalability / elasticity – Optimistic replication NoSQL Databases Mar 2010 #41
- 42. Cassandra – data model, partitioning • Data model – Same as BigTable – Super Columns (nested Columns) and Super Column Families – column order in a CF can be specified (name, time) • Cluster membership – Gossip – every nodes gossips to 1-3 other nodes about the state of the cluster (merge incoming info with its own) – Changes in the cluster (node in/out, failure) propagate quickly (LogN) – Probabilistic failure detection (sliding window, Exp(α) or Nor(μ,σ2)) • Dynamic partitioning – Consistent hashing – Ring of nodes – Nodes can be “moved” on the ring for load balancing NoSQL Databases Mar 2010 #42
- 43. Cassandra - operations • Writes (== BigTable… almost) – Client sends request to a random node, the node determines the actual node responsible for storing the data (cluster awareness) – Data replicated to N nodes (config) – Data first added to the commit log, then to the memtable, eventually flushed to SSTable • Reads (== BigTable… almost) – Send request to a random node, which forwards it to all the N nodes having the data • Single read – return first response / Quorum read – value that the majority of nodes agrees on – First read from memtable, if info is incomplete then read the SSTables – Bloom filters for efficient SSTable lookups • Compactions (== BigTable) Databases NoSQL Mar 2010 #43
- 44. Cassandra @ Facebook • Inbox search • ca. 2009 - 50 TB data, 150 nodes, 2 datacenters • Performance (production) (C) facebook NoSQL Databases Mar 2010 #44
- 45. Contents Part IV Document stores CouchDB NoSQL Databases Mar 2010 #45
- 46. CouchDB • http://couchdb.apache.org/ , ~2005 • Schema-free, document oriented database – Documents stored in JSON format (XML in old versions) – B-tree storage engine – MVCC model, no locking – no joins, no PK/FK (UUIDs are auto assigned) – Implemented in Erlang • 1st version in C++, 2nd in Erlang and 500 times more scalable (source: “Erlang Programming” by Cesarini & Thompson) – Replication (incremental) { • Documents “name”: “Ontotext”, “url”: “www.ontotext.com” – UUID, version “employees”: 40 – Old versions retained “products”: [“OWLIM”, “KIM”, “LifeSKIM”, “JOCI”] } NoSQL Databases Mar 2010 #46
- 47. CouchDB (2) • REST API CRUD HTTP params Create PUT /db/docid Read GET /db/docid Update POST /db/docid Delete DELETE /db/docid • Views – Filter, sort, “join”, aggregate, report – Map/Reduce based, language independent (JavaScript by default) – K/V pairs from Map/Reduce are also stored in the B-tree engine – Built on demand – Can be materialized & incrementally updated NoSQL Databases Mar 2010 #47
- 48. CouchDB – views (C) Chris Anderson / Apache NoSQL Databases Mar 2010 #48
- 49. Contents Part V Benchmarks NoSQL Databases Mar 2010 #49
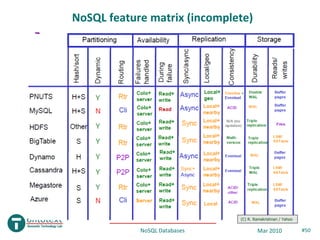
- 50. NoSQL feature matrix (incomplete) (C) R. Ramakrishnan / Yahoo NoSQL Databases Mar 2010 #50
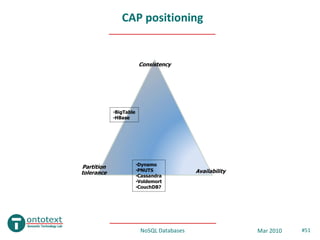
- 51. CAP positioning Consistency •BigTable •HBase •Dynamo Partition tolerance •PNUTS Availability •Cassandra •Voldemort •CouchDB? NoSQL Databases Mar 2010 #51
- 52. Yahoo Cloud Serving Benchmark (YCSB) • Benchmark various NoSQL systems – Performance • Measure latency/throughput curve on a fixed hardware – Scale out (elasticity) • add hardware, increase data size / workload proportionally • Measure latency (best case: constant) • Or… add hardware but same data/workload (latency should drop) – Later – replication, availability, … • Testbed – 6 boxes {2x4 core 2.5GHz, 8GB RAM, 6 HDD (SAS RAID1+0), GB eth} – 120M records (1K) ~ 20GB data per server – 100+ client threads NoSQL Databases Mar 2010 #52
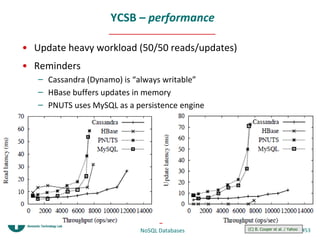
- 53. YCSB – performance • Update heavy workload (50/50 reads/updates) • Reminders – Cassandra (Dynamo) is “always writable” – HBase buffers updates in memory – PNUTS uses MySQL as a persistence engine NoSQL Databases (C) B. Cooper et al. / Yahoo #53 Mar 2010
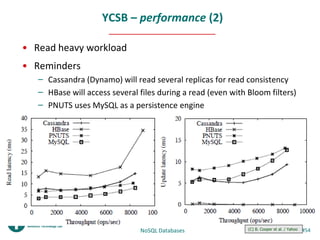
- 54. YCSB – performance (2) • Read heavy workload • Reminders – Cassandra (Dynamo) will read several replicas for read consistency – HBase will access several files during a read (even with Bloom filters) – PNUTS uses MySQL as a persistence engine NoSQL Databases (C) B. Cooper et al. / Yahoo #54 Mar 2010
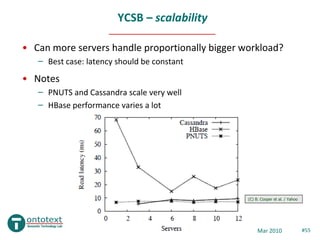
- 55. YCSB – scalability • Can more servers handle proportionally bigger workload? – Best case: latency should be constant • Notes – PNUTS and Cassandra scale very well – HBase performance varies a lot (C) B. Cooper et al. / Yahoo NoSQL Databases Mar 2010 #55
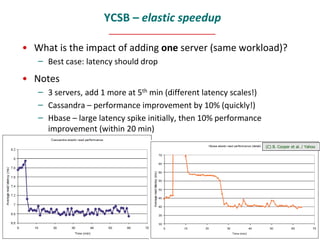
- 56. YCSB – elastic speedup • What is the impact of adding one server (same workload)? – Best case: latency should drop • Notes – 3 servers, add 1 more at 5th min (different latency scales!) – Cassandra – performance improvement by 10% (quickly!) – Hbase – large latency spike initially, then 10% performance improvement (within 20 min) (C) B. Cooper et al. / Yahoo NoSQL Databases Mar 2010 #56
- 57. Contents Part VI RDF & NoSQL? NoSQL Databases Mar 2010 #57
- 58. RDF & NoSQL • No easy match – Partitioning by key not so suitable for RDF (S, P, O) – Data locality insufficient for RDF materialisation – Full featured query language (SPARQL) cannot be efficiently mapped to NoSQL key/value lookups and range scans – Eventual consistency is a problem (materialisation with stale data) • So far RDF limited to the graph databases subset of NoSQL – But graph databases don’t provide massive scalability NoSQL Databases Mar 2010 #58
- 59. Useful links • http://groups.google.com/group/nosql-discussion • “Bigtable: A Distributed Storage System for Structured Data” • “Cassandra - A Decentralized Structured Storage System” • "Dynamo: Amazon’s Highly Available Key-value Store" • “PNUTS: Yahoo!'s Hosted Data Serving Platform” • “Benchmarking Cloud Serving Systems with YCSB” • “HBase vs. BigTable Comparison” NoSQL Databases Mar 2010 #59
- 60. Q&A Questions? NoSQL Databases Mar 2010 #60